简介
本次研讨会由中国人工智能学会青年工作委员会主办,哈尔滨工业大学深圳研究生院和南京理工大学协办。该研讨会旨在为从事计算机视觉领域的知名学者和研究人员提供一个学科研究互动平台,促进和加强领域内的学术交流和合作。研讨会将邀请多位知名专家学者做主题报告,分享和讨论计算机视觉领域最新最热的理论研究方法和应用,使与会者接触到计算机视觉领域目前最前沿的研究工作和团队。
组委会
| 组织委员会 | 徐勇(哈尔滨工业大学深圳研究生院) |
| 杨健(南京理工大学) |
日程安排
8月29日(周一) 紫荆山庄 8号楼B1层综合会议室 |
|||
| 08:00-08:30 | 会议现场签到 |
||
| 时间 | 内容 | ||
| 08:30-08:40 | 开幕式 | ||
| 08:40--09:30 | 报告1:胡卫明 博士,中国科学院自动化研究所 研究员 视觉运动跟踪与行为理解 |
||
| 09:30-10:20 | 报告2:张长水 博士,清华大学 教授 Image Caption with Region-Based Attention and Scene Factorization |
||
| 10:20-10:35 | 茶 歇 |
||
| 10:35-11:25 | 报告3:林宙辰 博士,北京大学 教授 Learning Partial Differential Equations for Computer Vision and Image Processing |
||
| 12:00-13:30 | 午餐、休息 |
||
| 13:45-14:35 | 报告4:吴飞 博士,浙江大学 教授 跨媒体群智计算 |
||
| 14:35-15:25 | 报告5:王晓刚 博士,香港中文大学 副教授 Understanding Deep Learning and Neural Semantics |
||
| 15:25-16:15 | 小组讨论 | ||
* * *
特邀报告
胡卫明
 中国科学院自动化所 研究员
中国科学院自动化所 研究员
- 题目
- 视觉运动跟踪与行为理解
- 摘要
- 视觉运动分析是视频智能化处理的一个最重要的研究课题。视觉运动分析的研究内容从低层到高层,包括底层视觉特征提取、目标运动检测、目标跟踪、目标行为模式的学习和目标行为的语义描述。本讲座主要介绍视频运动分析中的如下几方面内容:1) 基于半监督张量图嵌入学习的目标跟踪算法,对张量空间内在局部几何结构进行建模从而保留更多判别信息,通过迁移学习和半监督策略来调整嵌入空间,使得算法能在跟踪过程中区分前景和背景。2) 基于增量狄里克雷混合模型、对偶分层狄里克雷过程-隐马尔科夫模型的目标运动模式学习,能同时确定主题数目、获取单词之间的时序关系和建模文档类。3) 基于上下文随机游走图核的行为识别,将结构化图表示与统计学习相结合并挖掘图的局部拓扑结构特征,再用L1,2正则项的泛化多核算法将不同步长对应的图核融合起来识别目标行为。
- 报告人简介
张长水
 清华大学 教授
清华大学 教授
- 题目
- Image Caption with Region-Based Attention and Scene Factorization
- 摘要
-
Learning sequence is a challenge task. Recent progress on automatic generation of image captions has shown that it is possible to describe the most salient information conveyed by images with accurate and meaningful sentences. In this talk, we introduce some models for sequence modeling. Then we introduce our image caption system that exploits the parallel structures between images and sentences. In our model, the process of generating the next word, given the previously generated ones, is aligned with the visual perception experience where the attention shifting among the visual regions imposes a thread of visual ordering. This alignment characterizes the flow of "abstract meaning", encoding what is semantically shared by both the visual scene and the text description. Our system also makes another novel modeling contribution by introducing scene-specific contexts that capture higher-level semantic information encoded in an image. The contexts adapt language models for word generation to specific scene types. We benchmark our system and contrast to published results on several popular datasets. We show that using either region-based attention or scene-specific contexts improves systems without those components. Furthermore, combining these two modeling ingredients attains the state-of-the-art performance.
- 报告人简介
- 张长水, 男,1965 年出生,1986 年7 月毕业于北京大学数学系,获得学士学位。1992年7 月毕业于清华大学自动化系,获得博士学位。1992 年7 月至今在清华大学自动化系工作。现任清华大学自动化系教授、博士生导师,主要研究兴趣包括:机器学习、模式识别、计算视觉等方面。目前是计算机学会高级会员;担任学术期刊:”Pattern Recognition”, “计算机学报”,”自动化学报”等编委;在国际期刊发表论文100多篇,在顶级会议上发表论文50多篇。
林宙辰
 北京大学 教授
北京大学 教授
- 题目
- Learning Partial Differential Equations for Computer Vision and Image Processing
- 摘要
-
Many computer vision and image processing problems can be posed as solving partial differential equations (PDEs). However, designing PDE system usually requires high mathematical skills and good insight into the problems. In this paper, we consider designing PDEs for various problems arising in computer vision and image processing in a lazy manner: learning PDEs from training data via optimal control approach. We first propose a general intelligent PDE system which holds the basic translational and rotational invariance rule for most vision problems. By introducing a PDE-constrained optimal control framework, it is possible to use the training data resulting from multiple ways (ground truth, results from other methods, and manual results from humans) to learn PDEs for different computer vision tasks. The proposed optimal control based training framework aims at learning a PDE-based regressor to approximate the unknown (and usually nonlinear) mapping of different vision tasks. The experimental results show that the learnt PDEs can solve different vision problems reasonably well. In particular, we can obtain PDEs not only for problems that traditional PDEs work well but also for problems that PDE-based methods have never been tried before, due to the difficulty in describing those problems in a mathematical way.
- 报告人简介
-
Zhouchen Lin received the Ph.D. degree in applied mathematics from Peking University in 2000. He is currently a Professor at Key Laboratory of Machine Perception (MOE), School of Electronics Engineering and Computer Science, Peking University. His research interests include computer vision, image processing, machine learning, pattern recognition, and numerical optimization. He is an area chair of CVPR 2014/2016, ICCV 2015 and NIPS 2015 and a senior program committee member of AAAI 2016/2017 and IJCAI 2016. He is an associate editor of IEEE Trans. Pattern Analysis and Machine Intelligence and International J. Computer Vision.
吴 飞
 浙江大学 教授
浙江大学 教授
- 题目
- 跨媒体群智计算
- 摘要
-
个体间协作、竞争和激励等隐性交互所产生的海量众包数据蕴含着丰富群智,研究众包数据驱动与群体智慧协同的知识发现算法和模型变得十分重要。以“群体之间的强弱链接、相互影响和差异性等产生群智”为思路,本报告将介绍异构序列数据学习(搜索引擎点击数据)、个体交互建模(Q-A问答数据)和差异性视觉感知(图文描述数据)等方面的研究,以在数据驱动学习方法中引入“众包数据”所蕴含的直觉和经验,建立合适的群智计算模型。
- 报告人简介
-
浙江大学教授,博士生导师。主要研究领域为人工智能、跨媒体计算、多媒体分析与检索和统计学习。目前担任浙江大学计算机学院副院长、浙江大学人工智能研究所所长。教育部新世纪优秀人才支持计划入选者(2011年度)、浙江省151人才工程第二层次培养人员(2012年)。于2009年10月至2010年8月在美国科学院院士、加州大学伯克利分校统计系前任系主任郁彬(Bin Yu)教授课题组做访问学者。目前主持973课题1项、国家自然科学基金-浙江两化融合联合基金重点项目1项。担任SCI期刊Multimedia System副主编(Associate Editor)、SCI期刊Frontiers of Information Technology & Electronic Engineering (中国工程院子刊) 编委会成员 (Members of the Editorial Board)、中国图象图形学会计算机动画与数字娱乐专委会副主任兼秘书长、中国计算机学会多媒体技术专业委员会常务委员。
王晓刚
 香港中文大学 副教授
香港中文大学 副教授
- 题目
- Understanding Deep Learning and Neural Semantics
- 摘要
-
Deep learning has achieved great success in computer vision. Many people believe that the success is due to employing a huge number of parameters to fit big training data. In this talk, I will show that neuron responses of deep models have clear semantic interpretation, which is supported by our research on multiple fields of face recognition, object tracking, human pose estimation, and crowd video analysis. In particular, the responses of neurons in the top layers have sparseness and strong selectiveness object classes, attributes and identities. Sparseness and selectiveness are strongly correlated. Such selectiveness is naturally obtained through large scale training without adding extra regularization during the training process. By understanding neural semantics, we are inspired to develop new network architectures and training strategies and they effectively improve a broad range of applications in face recognition, face detection, compressing neural networks, object tracking, learned structured feature representation in human pose estimation, and effectively learning dynamic feature representations of different semantic units in video understanding.
- 报告人简介
-
Xiaogang Wang received his Bachelor degree in Electronic Engineering and Information Science from the Special Class of Gifted Young at the University of Science and Technology of China in 2001, M. Phil. degree in Information Engineering from the Chinese University of Hong Kong in 2004, and PhD degree in Computer Science from Massachusetts Institute of Technology in 2009. He is an associate professor in the Department of Electronic Engineering at the Chinese University of Hong Kong since August 2009. He received PAMI Young Research Award Honorable Mention in 2016, the Outstanding Young Researcher in Automatic Human Behaviour Analysis Award in 2011, Hong Kong RGC Early Career Award in 2012, and Young Researcher Award of the Chinese University of Hong Kong. He is the associate editor of the Image and Visual Computing Journal, Computer Vision and Image Understanding, IEEE Transactions on Circuit Systems and Video Technology. He was the area chair of ICCV 2011, ICCV 2015, ECCV 2014, ECCV 2016, ACCV 2014, and ACCV 2015. His research interests include computer vision, deep learning, crowd video surveillance, object detection, and face recognition.
报告下载
张长水:Image Caption with Region-Based Attention and Scene Factorization
林宙辰:Learning Partial Differential Equations for Computer Vision and Image Processing
王晓刚:Understanding Deep Learning and Neural Semantics
会场
深圳市南山区丽紫路1号
紫荆山庄 8号楼B1层综合会议室
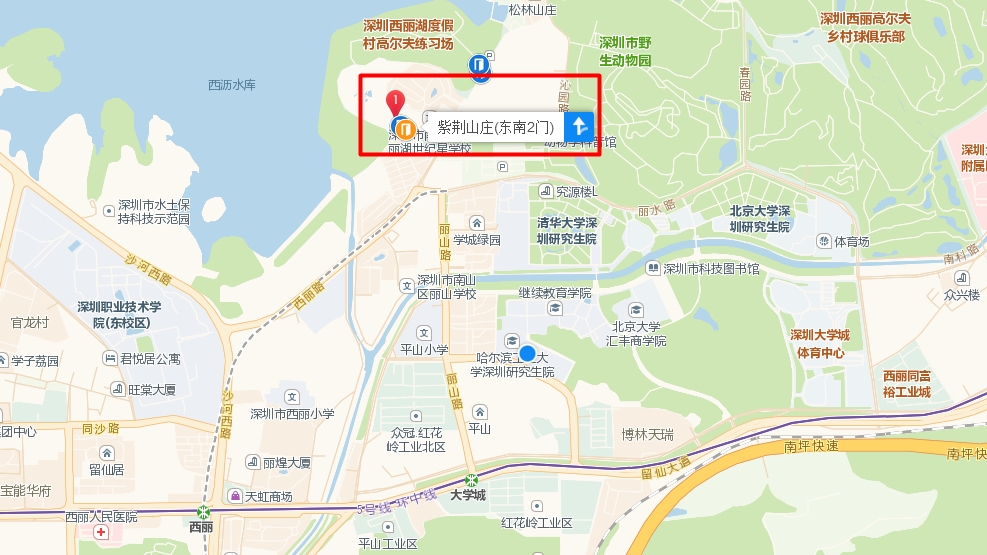
酒店位置
交通
从深圳宝安国际机场前往会场:
- 深圳宝安国际机场T3航站楼 到地铁11号线机场站(福田方向) 到前海湾下车。
- 前海湾站 换乘 5号线环中线(黄贝岭方向)大学城地铁站 C口出。
- 大学城地铁站步行150米 桃源康复中心 上车 36路公交车 至 动物园站 向北步行200米到达。
从深圳北站前往会场:
- 搭乘地铁5号线环中线 从深圳北站(前海湾方向)往大学城地铁站 C口出。
- 大学城地铁站步行150米 桃源康复中心 上车 36路公交车 至 动物园站 向北步行200米到达。
联系方式
报名方式
报名人数已达到上限,谢谢大家的合作。