Natural Scene Character Recognition Datasets
There are four publicly available datasets, i.e. Char74K dataset, ICADAR 2003 robust character recognition dataset, IIIT5K set and Street View Text (SVT) dataset. We only focus on recognition of English characters, which are composed of 62 classes, i.e. digits 0~9, English letters in upper case A~Z, and lower case a~z. (Project Page)
Visible Light and Near-infrared Human Face Database
Lab1 and Lab2 are two database of images of human faces. Images were taken in strictly controlled different illumination environments. Images from different illumination environments mimic the real-world conditions and enable robust face recognition algorithms testing. All the images were captured from the volunteers of HITSZ. The Lab1 and Lab2 databases are free of charge, if the researcher agrees to the following restrictions on the databases:
1. The Lab1 and Lab2 databases will not be further distributed, published, or copied in any way or form whatsoever, whether for profit or not.
2. All the images will be used for the purpose of academic or scientific research only.
3. For protecting the privacy of the database participants, the images will not be used for any commercial materials in any form.
4. The published documents and papers that use any of these two databases should cite the following paper: " Yong Xu, Aini Zhong, Jian Yang and David Zhang, "Bimodal biometrics based on a representation and recognition approach", Opt. Eng. 50(3), 037202, 2011, (SCI).", which first used and introduced these two databases. (paper)
5. We encourage the authors send the copies of all documents and papers that use the two databases to Prof. Yong Xu, email: yongxu@ymail.com
The Lab1 database simultaneously contains visible light images and near-infrared images of the volunteers. There are 50 subjects, and each has 10 visible light images and 10 near-infrared images. The size of every image is 100 by 80.
The Lab2 also simultaneously contains visible light images and near-infrared images of the volunteers (subjects). There are 50 subjects. Each subject provides twenty visible light face images and the same number of near-infrared face images. These images were acquired under the following four different illumination conditions: (a) under the environment illumination (referred to as ‘normal illumination’) condition, (b) under the condition of the environment illumination plus the illumination of the left incandescent lamp (referred to as ‘left illumination’), (c) under the condition of the environment illumination plus the illumination of the right incandescent lamp (referred to as ‘right illumination’), (d) under the condition of the environment illumination plus the illumination of the left and the right incandescent lamps (referred to as ‘both illumination’). The size of every face image is 200 by 200. The face images also have variation in facial expression and pose. The number at the second bit of the file name has the following denotations: 1――‘both illumination’,2――‘left illumination’,3――‘right illumination’,4――‘normal illumination’.
Download: Lab1 Lab2_Part1 Lab2_Part2
Dataset
This dataset provides the ground truths of four sequences (Three sequences are captured by ourselves, the other one is from Pets 2006 S7).They are typical indoor visual data in surveillance scenarios. The dataset includes the challenge of large size of occlusion. We manually labeled the ground truths of every 10-th frame in each sequence. All the sequences are free of charge, if the researcher agrees to the following restriction on the dataset:
- All the images are used for the purpose of academic or scientific research.
- For protecting the privacy of the database participants, the images will not be used for any commercial materials in any form.
- The published documents and papers that use any of these dataset should cite the following paper: “Jiajun Wen, Yong Xu, Jinhui Tang, Yinwei Zhan, Zhihui Lai, XiaotangGuo, ”Joint video frame set division and low-rank decomposition for background subtraction”, IEEE Transactions on Circuits and Systems for Video Technology". (paper)
- We encourage the authors send the copies of all documents and papers that use the database to Prof. Yong Xu, email: yongxu@ymail.com
The dataset contains 4 videos. Each individual image file (.rar) can be downloaded separately. The details related to these sequences are stated as follows:
(1) Sequence name: Fighting
Total number of the frames: 300
Description of the sequence: The sequence is captured by ourselves. Two people are chasing and fighting in a room.
(2) Sequence name: Walking I
Total number of the frames: 400
Description of the sequence: The sequence is captured by ourselves. Many people walk in a room, which results in occlusion.
(3) Sequence name: Walking II
Total number of the frames: 400
Description of the sequence: The sequence is captured by ourselves. Many people walk in a room, which results in a serious occlusion.
(4) Sequence name: Pets 2006 S7
Total number of the frames: 1200
Description of the sequence: The sequence is provided by Pets 2006 dataset. It also can be found at ftp://ftp.pets.rdg.ac.uk/pub/PETS2006/. However, the ground truths of the images are not provided at the above website. We manually labeled the ground truths of the images.
Download: Fighting Pets_2006_S7 Walking_I Walking_II
可见光与近红外人脸数据库
Lab1和Lab2为两个人脸数据库。其中的人脸图像是在严格控制的光照环境下采集的。不同的光照环境有利于模拟人脸识别的真实条件,也有利于验证人脸识别算法的鲁棒性。所有图像均采集自哈尔滨工业大学深圳研究生院的志愿者。Lab1和Lab2库供研究者免费使用,但研究者必须遵守以下协议:
1、无论是否以盈利为目的,使用者不可以任何形式和方式,传播、发表、拷贝Lab1和Lab2数据库。
2、这两个库中所有的图像只能被用于学术或科学研究。
3、为了保护这两个库中人员的隐私,其中的任何图像都不允许以任何形式在商业途径中发布。
4、所有使用到这两个库并公开发表的文档和论文都应引用如下论文:"Bimodal biometrics based on a representation and recognition approach", Opt. Eng. 50(3), 037202, 2011, (SCI)."(paper)
5、对于使用到这两个库并公开发表的文档或论文,作者应尽可能将发表的文档或论文发送拷贝至: yongxu@ymail.com
Lab1数据库包含可见光和近红外人脸图像。此库采集自50个志愿者,每人10幅可见光灰度图像和10幅近红外人脸图像。每幅图像的大小为100X80.
Lab2数据库包含可见光和近红外人脸图像。采集自50个志愿者,每人均有20幅彩色可见光人脸图像和20幅近红外人脸图像。 Lab2一共包含2000幅人脸图像。图像大小均为200X200。这些图像是在以下不同的光照条件下采集的:(a)自然光照 (b)自然光照+左侧光照 (c)自然光+右侧光照 (d)自然光照+左右侧灯同时光照。左右侧光照的光源均为白炽灯。图像也包含明显的姿态或表情变化。文件名中的第二位数字的指代意义如下:1――自然光照+左右侧灯同时光照,2――自然光照+左侧光照,3――自然光+右侧光照 ,4――自然光照
火焰检测数据集
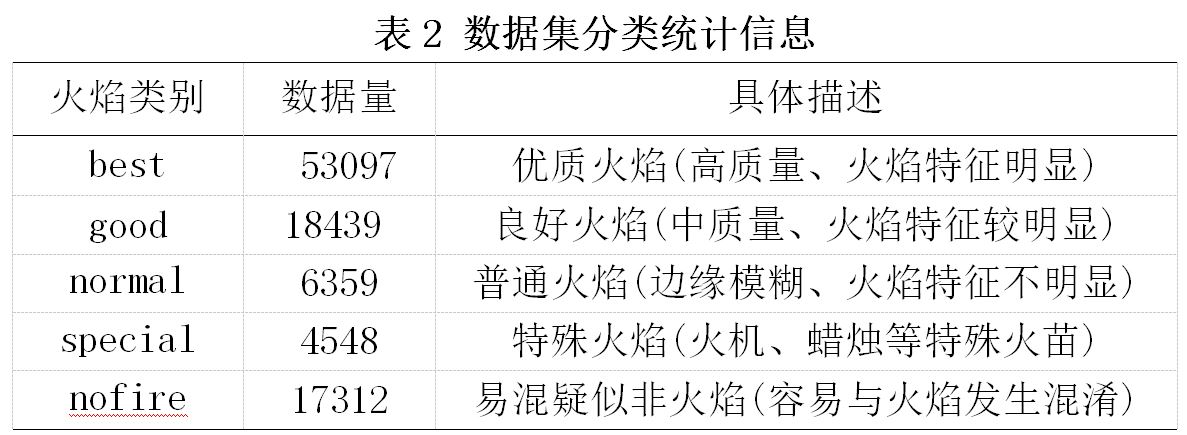
火焰数据集包括远距离、多目标、小目标、不同光照条件、黑夜条件下采集的82443张真实火焰图像和17312张易混疑似火焰图像。在火焰图像采集过程中,为确保数据集的多样性和丰富性,提高模型泛化性能。收集了不同来源的火焰图像,同时为有效降低误报率,收集了大量容易混淆的疑似火焰图像作为负样本。数据集主要来源包括KMU CVPR LabFire、Bilkent University火灾视频库、CorsicianFire、BoWFire、MIVIA、MS COCO2014、互联网火焰图像、自建火焰图像,其中以自建火焰图像为主。为保证数据集规范化,对数据集进行了统一格式化命名并逐张标注。最后为得到不同质量火焰数据,通过筛选分类将数据集分为best(优质火焰)、good(良好火焰)、normal(一般火焰)、special(特殊火焰)、nofire(易混火焰)五大类。火焰检测数据集供研究者免费使用,但研究者必须遵守以下协议:
1、无论是否以盈利为目的,使用者不可以任何形式和方式,传播、发表、拷贝火焰检测数据集。
2、火焰检测数据集中所有的图像只能被用于学术或科学研究。
3、为了保护火焰数据集中的隐私,其中的任何图像都不允许以任何形式在商业途径中发布。
4、对于使用到这个火焰库并公开发表的文档或论文,作者应将发表的文档或论文发送拷贝至:yongxu@ymail.com
火焰数据集的详细统计信息如表1所示:

首先是Corsician Fire数据集,包含595张火焰图像。然后是BoWFire数据集,包含119张火焰图像和107张易混疑似火焰图像。其次是CVPR Lab Fire、Bilkent University、MIVIA等公开视频集分帧图像。最后为增加数据集的多样性,分别从MS COCO2014数据集、百度、谷歌爬取了2000张火焰图像和17205张易混疑似火焰图像。
采集到的火焰图像均没有标签数据,因此使用LabelImg标注工具对每张火焰图像逐一标注并保存成VOC格式。对于负样本图像,通过生成YOLO格式空标签并存储在txt文件中。为保证82443张火焰图像的一致性和高质量,所有标签数据都逐一标注并手动多轮交叉检查。经过合计超过1800个工时的艰苦工作,完成了整个数据集中火焰区域的精确标记。
为了验证不同质量数据集对模型性能的影响,通过筛选分类将全部数据集分为五大类。 数据集分类统计信息如表2所示.
Download:FireDataset
|

